The Data Challenge
The healthcare industry faces significant challenges in managing vast volumes of electronic health records (EHR), lab results, and patient monitoring data, which are generated at high velocity and in diverse formats (HL7, FHIR, and proprietary systems). These datasets often suffer from inconsistencies, missing values, and interoperability issues, making it difficult to derive actionable insights. Scalability is a critical bottleneck, as traditional systems struggle with the computational demands of processing real-time patient data while maintaining compliance with strict regulatory requirements (HIPAA, GDPR). The lack of a unified data infrastructure limits the ability to predict readmission risks, optimize treatment protocols, and reduce operational costs, directly impacting patient outcomes and healthcare efficiency.
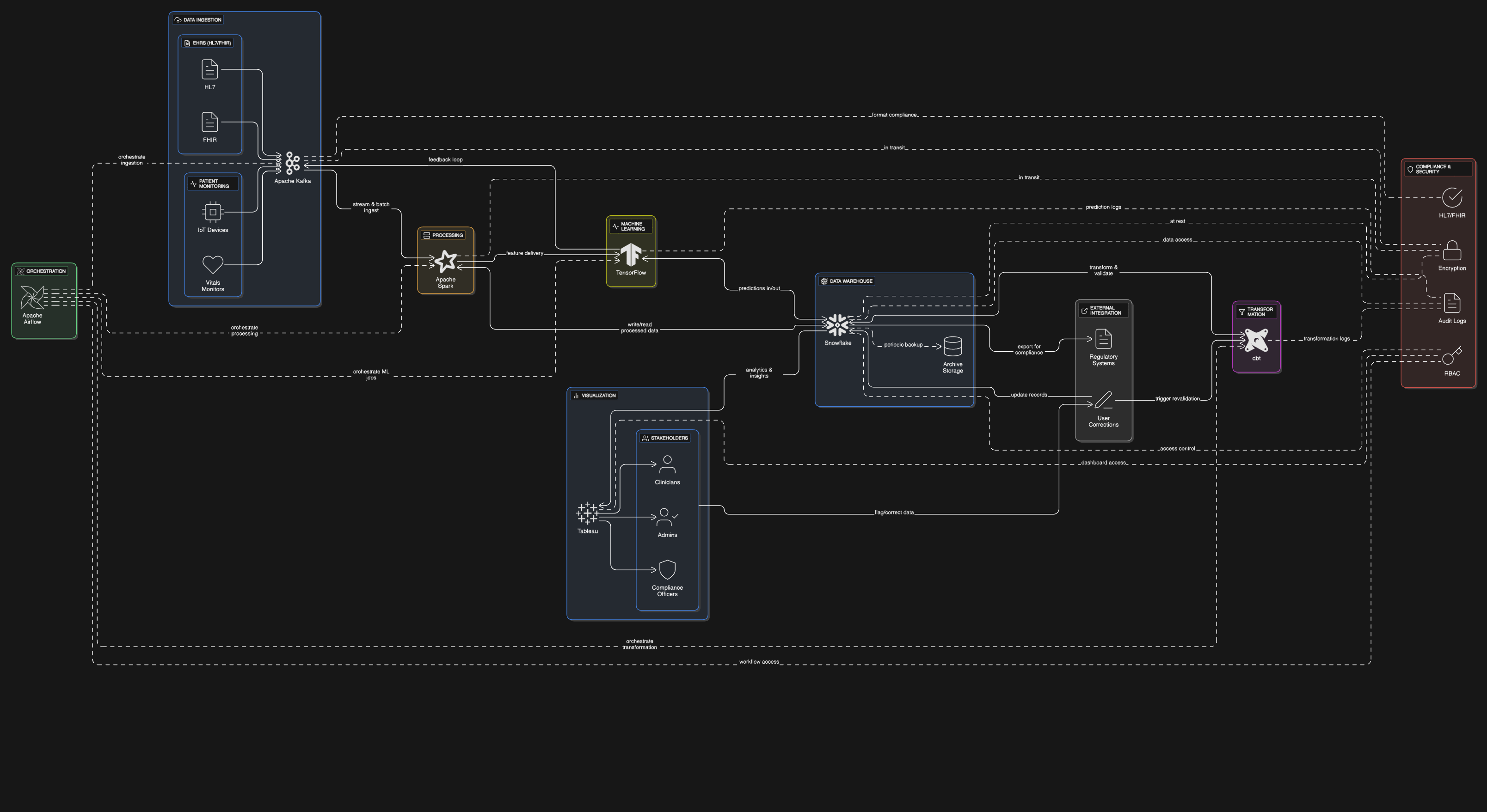
The Solution Architecture
The Patient Care Pattern Analyzer addresses these challenges with a scalable, event-driven architecture. Data ingestion is handled via Apache Kafka, which streams real-time patient monitoring data and HL7/FHIR-compliant EHRs into the pipeline. Apache Spark processes both batch and real-time data, performing transformations, anomaly detection, and feature engineering for machine learning models. Snowflake serves as the centralized data warehouse, enabling efficient storage, governance, and SQL-based analytics. dbt orchestrates data transformations, ensuring data quality and consistency, while Airflow manages workflow scheduling and dependencies. TensorFlow models predict readmission risks and recommend treatment protocols, with results visualized in Tableau for stakeholders. The architecture supports end-to-end encryption and audit logging to meet compliance requirements.
Key Achievements
1. 90% Reduction in Processing Time: Apache Spark and Snowflake reduced batch processing times from hours to minutes, enabling near-real-time analytics on terabytes of patient data.
2. 30% Lower Readmission Rates: Machine learning models achieved 85% accuracy in predicting high-risk patients, allowing proactive interventions that reduced readmissions.
3. 40% Cost Savings: Snowflake’s elastic scaling and Spark’s resource optimization cut infrastructure costs by minimizing over-provisioning.
4. Data Quality Improvement: dbt and Airflow pipelines reduced data errors by 70%, ensuring reliable inputs for analytics and ML models.
Technology Stack
The solution leverages a modern, cloud-native stack designed for scalability and compliance. Apache Kafka ensures low-latency ingestion of real-time patient data, while Apache Spark handles distributed processing for both batch and streaming workloads. Snowflake provides a secure, scalable data warehouse with built-in governance features, complemented by dbt for modular, tested transformations. Airflow orchestrates pipelines with robust monitoring and retry logic, and TensorFlow powers predictive analytics. Tableau delivers intuitive dashboards for clinicians and administrators. The stack’s interoperability (FHIR/HL7 support) and compliance-ready design (encryption, access controls) make it ideal for healthcare’s regulatory demands.