The Data Challenge
Enterprise Quarterly Business Reviews (QBRs) historically required analysts to manually extract, transform, and aggregate data from multiple siloed systems—Salesforce for CRM, Zendesk for customer support, and Jira for product development. This process consumed 20-40 analyst hours per quarter, introduced data consistency risks, and delayed strategic decision-making. The growing volume of enterprise data (10+ TB across sources) compounded these challenges, with disparate schemas, inconsistent data quality, and real-time synchronization needs. Legacy ETL pipelines lacked scalability, resulting in processing bottlenecks during peak periods. The business needed a unified, governed data platform capable of automating insights generation while maintaining strict compliance with data security policies.
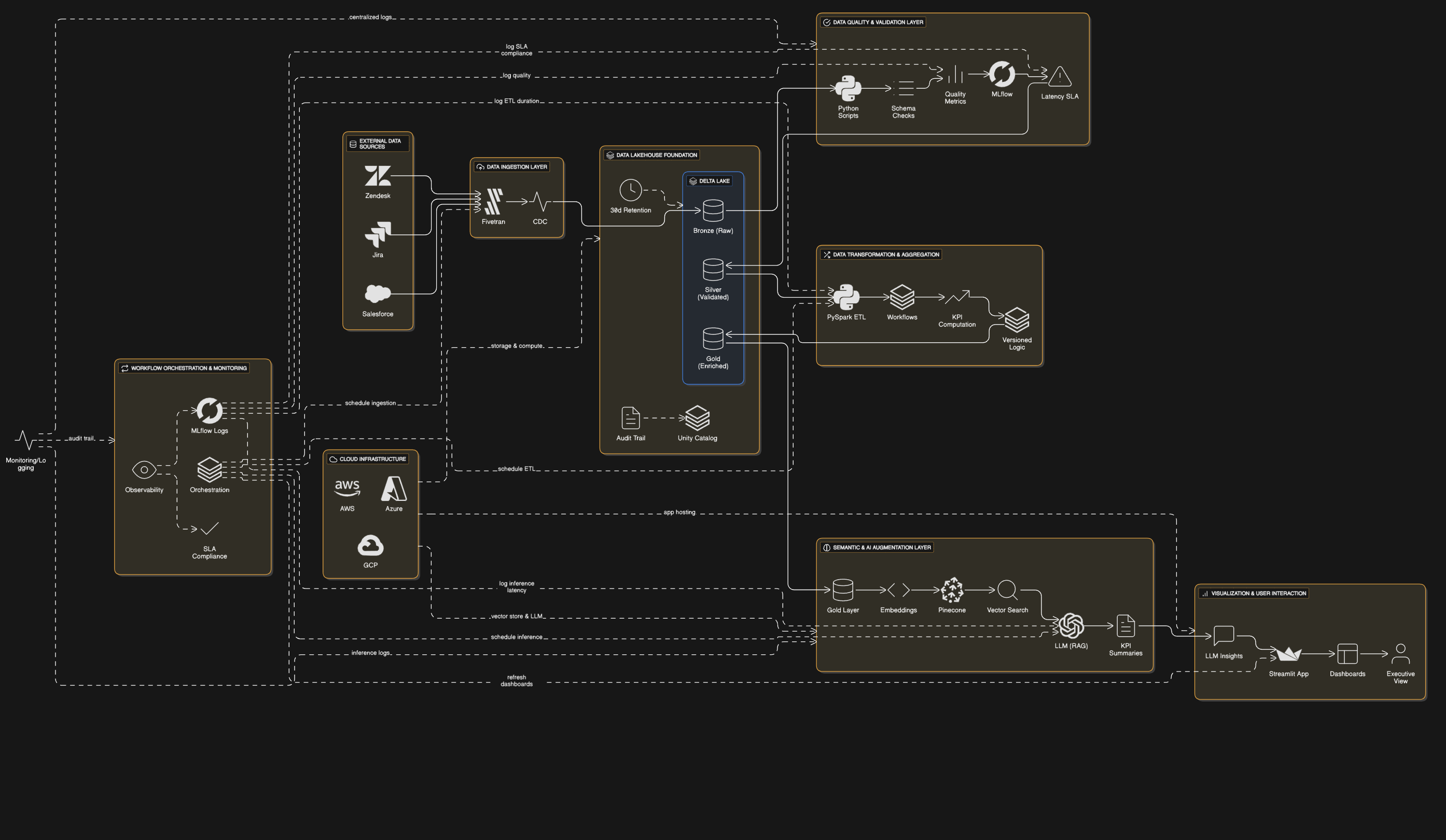
The Solution Architecture
The automation platform leverages a modern data lakehouse architecture on Databricks, with Delta Lake providing ACID transactions and schema enforcement. Fivetran handles CDC-based ingestion from Salesforce, Zendesk, and Jira into a bronze layer, while Python-based data quality checks validate schema conformity. Transformations in the silver layer use PySpark for windowed aggregations and KPI calculations, with business logic version-controlled in Unity Catalog. A vector-optimized gold layer in Pinecone enables semantic search across historical QBRs via RAG (Retrieval-Augmented Generation) with LLM integration. Streamlit serves as the presentation layer, dynamically rendering executive dashboards with AI-generated insights. The entire pipeline features Databricks Workflows for orchestration, with observability through custom MLflow tracking of data quality metrics and latency SLAs.
Key Achievements
1. 98% Reduction in QBR Preparation Time: Automated data processing reduced manual effort from 35 hours to 12 minutes per quarter, enabling real-time QBR generation on demand.
2. Data Accuracy Improvement: Unity Catalog-driven governance and automated validation rules decreased reporting errors by 72% compared to manual processes.
3. Infrastructure Cost Optimization: Serverless Databricks SQL and Delta Lake’s Z-ordering reduced compute costs by 45% while improving query performance 8x.
4. Actionable Intelligence Scaling: Vector search and LLM integration expanded analysis capacity from 3 standard KPIs to 120+ tracked metrics with contextual anomaly detection.