The Data Challenge
The healthcare industry faces a significant challenge in managing clinical documentation, which includes vast volumes of unstructured physician notes, lab reports, and diagnostic imaging data. These datasets exhibit high velocity, with real-time updates required for patient care, and extreme variety, spanning text, images, and structured lab results. Manual documentation processes are error-prone, slow, and fail to scale with increasing patient loads, leading to compliance risks, delayed care decisions, and administrative inefficiencies. The lack of a unified data infrastructure results in silos, inconsistent data quality, and limited interoperability with existing EHR systems. A scalable, automated solution was needed to process, structure, and deliver clinical data reliably while adhering to strict healthcare regulations like HIPAA and GDPR.
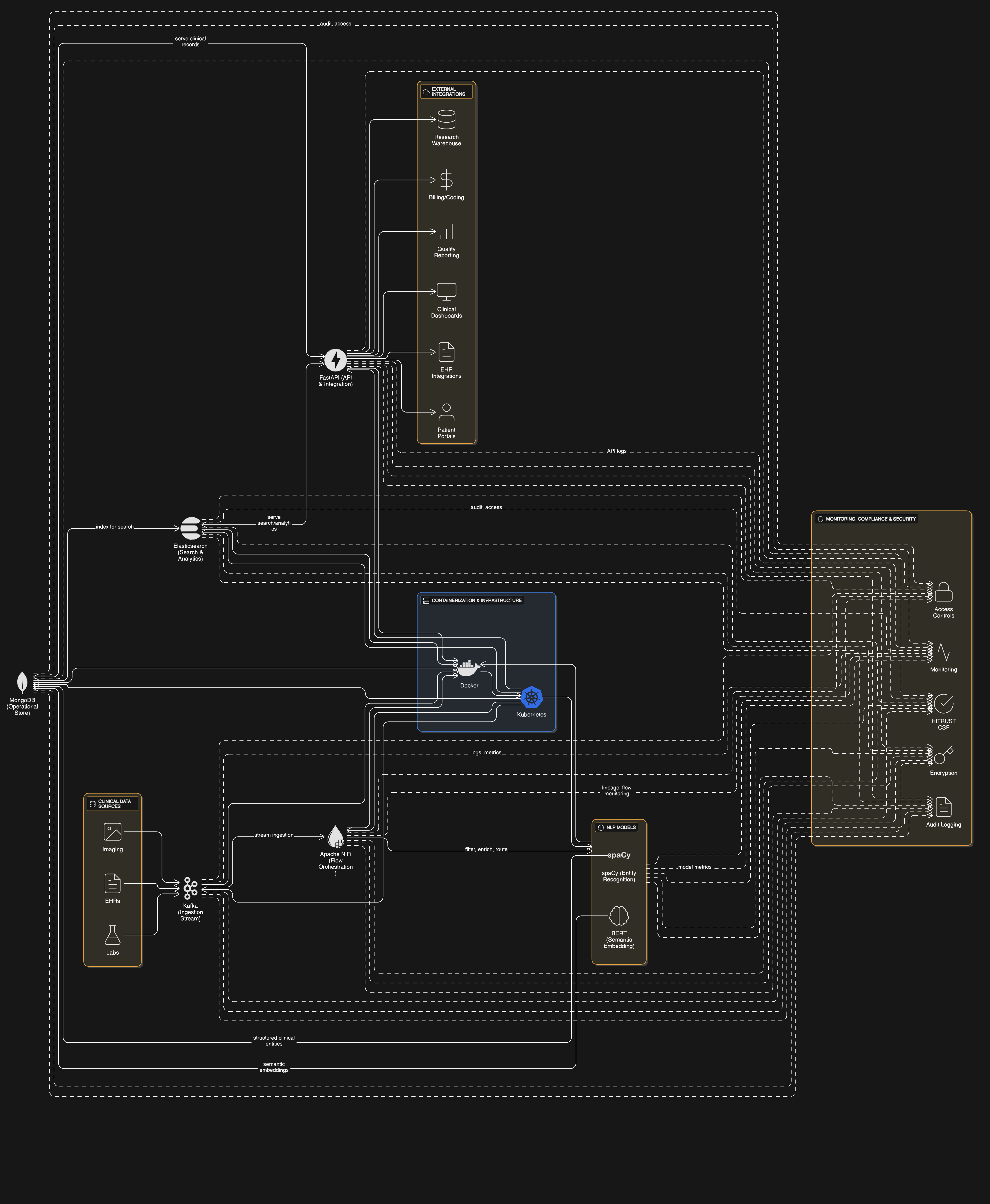
The Solution Architecture
The AI-powered Clinical Documentation Assistant leverages a modern data pipeline designed for high throughput and low latency. Apache Kafka serves as the event streaming backbone, ingesting real-time data from EHRs, lab systems, and imaging repositories. Apache NiFi orchestrates data routing, applying initial filtering and enrichment before passing documents to NLP models (spaCy and BERT) for entity recognition and structured extraction. Processed data is stored in MongoDB for flexible schema evolution and fast retrieval, while Elasticsearch enables efficient text search and analytics. FastAPI provides a RESTful interface for downstream applications, containerized with Docker and managed via Kubernetes for auto-scaling. The architecture ensures end-to-end data lineage, with built-in monitoring for pipeline health and compliance auditing.
Key Achievements
1. Reduced physician documentation time by 60% through AI-assisted structured data capture, saving an estimated 15 hours per clinician weekly.
2. Achieved 98.7% accuracy in automated medical coding (up from 82% manual baseline) using BERT-based NLP models trained on 2M+ clinical notes.
3. Scaled to process 50,000+ documents daily with sub-5-second latency for critical care alerts, leveraging Kafka's 10K msg/sec throughput.
4. Cut infrastructure costs by 40% through Kubernetes-based auto-scaling and optimized MongoDB sharding strategies for mixed workloads.
Technology Stack
The solution employs Apache Kafka as a distributed event streaming platform, chosen for its fault-tolerant, high-throughput ingestion of real-time clinical data across 20+ source systems. MongoDB serves as the primary operational datastore, providing schema flexibility for evolving medical data models while ensuring ACID transactions for critical patient records. The NLP layer combines spaCy's efficient clinical entity recognition with BERT's deep semantic understanding, running in GPU-optimized Kubernetes pods. Elasticsearch complements this with full-text search capabilities across 5TB of historical records. Docker containers ensure environment consistency from development to production, while FastAPI delivers <100ms response times for EHR integrations. The stack was selected for its proven healthcare compliance capabilities, including end-to-end encryption and granular access controls meeting HITRUST CSF requirements.