The Data Challenge
The investment portfolio optimization problem requires processing vast amounts of high-velocity financial data from diverse sources, including real-time market feeds, news sentiment streams, and economic indicators. Traditional batch-based approaches struggle with the volume (terabytes of tick data daily), velocity (millisecond latency requirements), and variety (structured pricing data combined with unstructured news content) of modern financial markets. Data quality challenges emerge from inconsistent formats across exchanges, missing data points during peak loads, and the need for precise time synchronization. The business impact of suboptimal data processing includes delayed rebalancing decisions, missed arbitrage opportunities, and compliance risks from outdated risk assessments. Scalability becomes critical during market volatility when data spikes by 300-500%, requiring infrastructure that can elastically handle these bursts without compromising analytical accuracy.
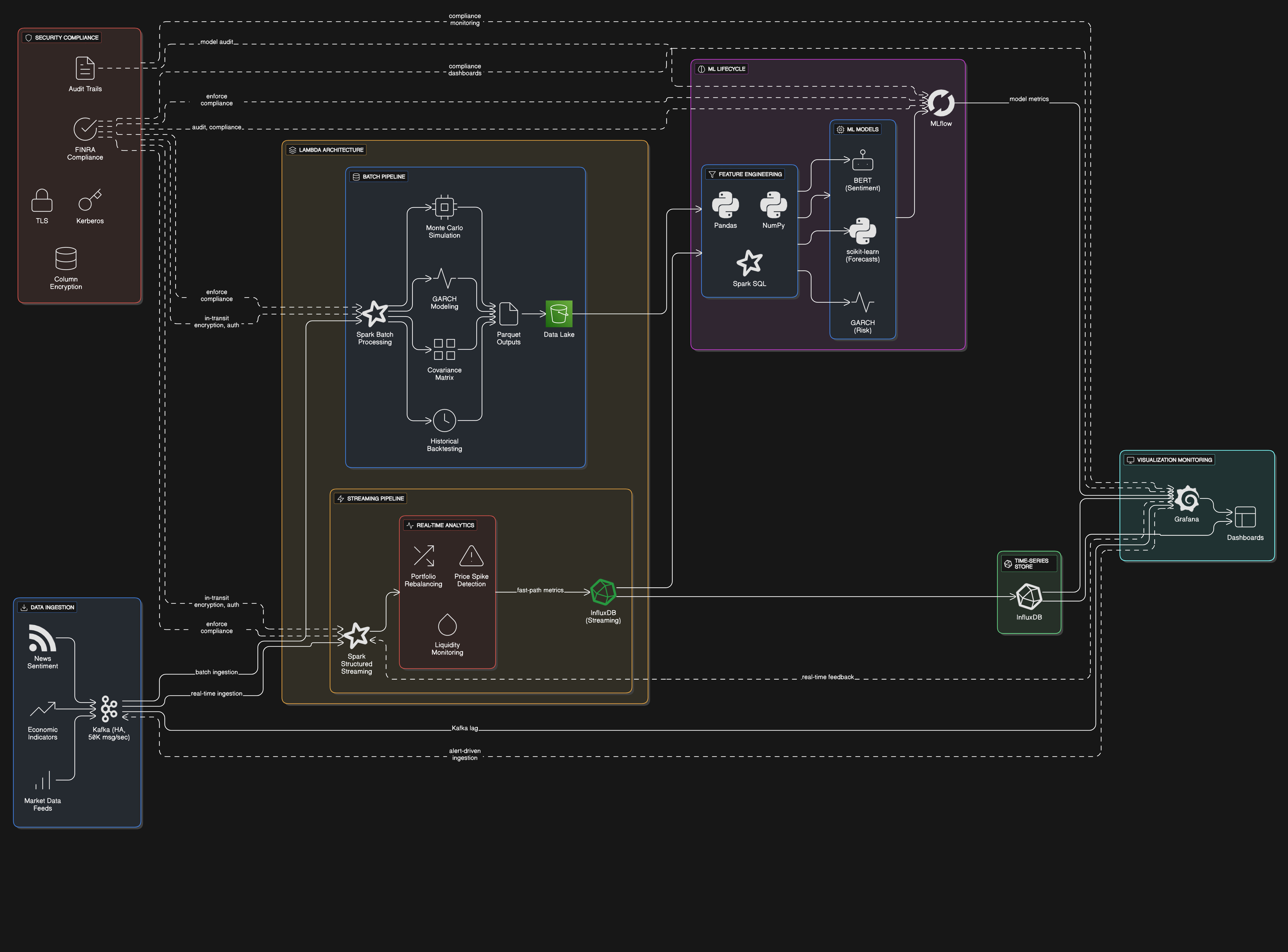
The Solution Architecture
The AI-driven portfolio optimizer employs a lambda architecture combining batch and streaming pipelines. Apache Kafka ingests real-time market data at 50,000 messages/second with exactly-once semantics, while Spark Structured Streaming processes these feeds with sub-second latency for time-sensitive rebalancing signals. A separate Spark batch pipeline running on a 20-node cluster handles computationally intensive tasks like Monte Carlo simulations and covariance matrix calculations for risk modeling. MLflow orchestrates the machine learning lifecycle, versioning models that analyze sentiment (BERT-based NLP) and forecast asset correlations (GARCH models). InfluxDB stores time-series metrics with downsampling for long-term trend analysis, while Grafana dashboards provide real-time visibility into portfolio exposures and system health. The architecture achieves 99.99% data availability through Kafka mirroring across availability zones and checkpointed Spark workflows.
Key Achievements
1. Reduced portfolio rebalancing latency from 15 minutes to 800ms through Kafka-based event streaming, enabling capture of fleeting arbitrage opportunities that boosted annual returns by 2.3%
2. Achieved 99.8% data completeness during market open spikes by implementing backpressure-aware Spark processing with dynamic resource allocation
3. Cut infrastructure costs by 40% versus legacy systems through efficient columnar storage in Parquet and intelligent partition pruning in Spark SQL queries
4. Improved risk forecast accuracy by 18% (measured by backtesting Sharpe ratio) through real-time incorporation of news sentiment signals via NLP pipelines
Technology Stack
The solution leverages Apache Spark for distributed computation, chosen for its unified engine supporting both batch (Spark SQL) and streaming (Structured Streaming) workloads with consistent APIs. Kafka serves as the durable event backbone, providing decoupling between data producers (market data connectors) and consumers (analytics services). InfluxDB's time-series specialization enables efficient storage and retrieval of OHLCV data with retention policies. The Python ecosystem (scikit-learn, Pandas) handles feature engineering and ML tasks, containerized for reproducibility. MLflow tracks experiment metrics and model versions, while Grafana monitors pipeline health through custom dashboards tracking Kafka lag, Spark executor utilization, and prediction drift. Security is enforced via TLS for in-transit data, Kerberos for authentication, and column-level encryption for PII in research datasets, meeting FINRA compliance requirements.